![[백엔드 기초] 7. DB Parallelization](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Ft1.daumcdn.net%2Fcfile%2Ftistory%2F99E5143660B6074420)

Scale up vs Scale out
Scale up vs Scale out
| 구분 | Scale up | Scale out |
|---|---|---|
| 명칭 | 스케일업 | 스케일아웃 |
| 관점 | 서버의 하드웨어 성능을 높이는 것 | 서버의 수를 증가 |
| 설명 | · 보통 말하는 업그레이드 · CPU 클럭 속도, 코어 수 나 메모리 그리고 하드디스크 등 서버자원을 추가하여 처리능력을 향상시키는 방식. · 기존 스토리지에 필요한 만큼의 용량 증가 | · 동일한 서버/DBMS를 병렬로 구축 · 용량과 성능 요구조건에 맞추기 위해 node단위 (스토리지)로 증가되고 하나의 시스템처럼 운영 · 서버의 수를 증가시켜서 처리능력을 향상시키는 방식 · 여러 대의 서버를 하나의 시스템으로 인식시키는 방법 |
| 비용 | · 컨트롤러나 네트워크 인프라 비용은 별도로 발생하지 않고 디스크만 추가 · 성능이 증가하는 것에 비해 가격증가가 더 커 비용이 부담될 수 있음 | · 추가된 노드들이 하나의 시스템으로 운영되기 위한 NW장비 필요, 컨트롤러도 추가 · 상대적으로 저렴 |
| 용량 | · 하나의 스토리지 컨트롤러에 붙일 수 있는 Device가 한정되어있기 때문에 용량 확장에 제약. | · Scale up형태의 스토리지보다는 용량 확장성이 크지만 무한대로 확장하지는 않음 |
| 성능 | · 하드웨어 성능 높아지나 전체적인 성능 향상은 기대하기 어려움 | · Multiple storage controller의 IOPS, 대역폭 등이 합친 성능· 추가된 서버들이 하나의 시스템으로 인식 시키기 위한 별도의 네트워크 장비가 필요하며 스토리지 용량 확장성이 매우 좋음. · 노드 수를 추가형 계속적인 성능 향상이 가능하지만 효율은 상대적으로 떨어짐 |
| 복잡성 | · 심플한 구성 | · 상대적으로 복잡 |
| 가용성 | · 변화 X | · 노드가 추가될수록 가용성이 높아짐 |
| 시스템 | Tiglely-Coupled System | Loosely Coupled System 분산 컴퓨팅(Distributed Computing) |

Scale Out (스케일 아웃)
기존 서버와 비슷한 사양의 서버의 대수를 추가해 여러대의 서버를 두는 방법.
- 스케일 업 보다는 인프라 재구성에 있어서 다소 유연한 방법
- 비용이 스케일 업 방식에 비해 저렴하고 지속적 확장 가능
- 용량, 성능 확장의 한계가 없음. 하드웨어를 변경하는것이 아닌, 비슷한 성능의 서버를 여러개 두는 방법이기 때문에 지속적인 확장이 가능.
- 하나의 서버가 모든 트래픽을 관리하는 스케일 업 방식과 반대로, 여러개의 서버를 두어 분산처리하기때문에 장애 가능성이 감소. 즉, 단일 서버에 작업이 쌓여서 멈춰있는 병목현상을 줄일 수 있음.
- 일부 서버가 장애 등으로 중단되더라도 다른 서버에서 요청을 처리하면 되므로 안정적인 서비스 가능
- 요청이 들어오는 걸 여러 장비에서 처리할 수 있도록 각 요청을 나눠줄 수 있는 로드밸런싱(Load Balancing)이 필수적임
- 여러 서버에서 처리해도 무관한 web server, web application server 등에 적합
- 클라우드 서비스에서는 자원 사용량을 모니터링하여 자동으로 자원을 증설하는 Auto Scaling기능도 제공하는데, 이 때 사용되는 성능 향상 방식은 Scale Out을 의미하는 경우가 대부분
- 분산처리/병렬처리 방식이라고 생각하면 쉬움
- 병렬 컴퓨팅 환경을 구성하고 유지하려면 로드 밸런싱에 대한 높은 이해도가 요구됨.
- 병렬 컴퓨팅 환경 : 여러 개의 프로세서를 통해 하나의 프로그램을 처리하는 환경
- 로드 밸런싱 : 로드(=부하), 밸런싱(=부하)로, 한대의 서버로 부하가 집중되지 않도록 트래픽을 관리
Scale Out 의 단점
- 병렬 컴퓨팅은 어려움(설계, 구현)
- 기본적으로 직렬화(단일 처리) 되어야 할 부분 존재
- 기술적 측면에서의 문제점(대역폭, 동기화 문제)
- 동기화 측면: 코어가 증가함에 따라 마냥 성능이 증가하지 않음.
- 대역폭의 유한성: 코어 증가에 따라 대역폭은 기하급수적으로 증가하여 지연 발생 가능
Partitioning
DB에서 큰 Table이나 인덱스를 관리하기 쉬운 단위로 분리하는 방법
하나의 DBMS가 많은 Table을 관리하다 보니 느려지는 이슈가 발생.
이러한 이슈를 해결하기 위한 하나의 방법이 바로 파티셔닝(Partitioning)
장점
가용성(Availability)
- 물리적인 Partitioning으로 인해 전체 데이터의 훼손 가능성이 줄어들고 데이터 가용성이 향상
관리용이성(Manageability)
- 큰 Table들을 제거하여 관리를 쉽게 해줌
성능(Performance)
- 특정 DML과 Query의 성능을 향상시킴, 주로
대용량 Data Write환경에서 효율적.
- 많은 Insert가 있는 OLTP 시스템에서 Insert 작업들을 분리된 파티션들로 분산시켜 경합을 줄임.
Sharding
같은 테이블 스키마를 가진 데이터를 다수의 데이터베이스에 분산하여 저장하는 방법 (shard: 조각, 파편)

application level에서도 가능하지만 database level에서도 가능.
Horizontal Partitioning이라고 볼 수 있음.

- shards: 샤딩을 통해 나누어진 블록들.
- 샤딩은 데이터를 작은 덩어리(smaller chunks)로 쪼개는 것이고, 이 작은 덩어리를 logical shards라고 부름.
- logical shards는 분리된 physical shard, 즉 database node(데이터베이스의 인스턴스)에 뿌려짐.
- 주로 application level에서 실행됨 (여기서 application이란 어떤 shards에 읽기와 쓰기를 전송할지를 정의하는 코드를 포함하고 있는 것)
- Oracle, MySQl, PostgreSQL 등 일부 데이터베이스 관리 시스템은 내장된 sharding 능력이 있어서 database level에서 바로 사용 가능
- 분할된 테이블들이 물리적으로 서로 다른 노드에 저장될 경우 각 샤드 별 분산/병렬처리를 통해 효율적으로 질의를 처리
Partitioning과의 차이
- 보통 partitioning을 한다고 했을 때는 하나의 데이터베이스 안에서 이루어지는 경우를 지칭.
- 이에 비해, 샤딩은 물리적으로 다른 데이터베이스에 데이터를 수평 분할 방식으로 분산 저장하고 조회하는 방법
- 자주 혼용해서 씀
장점
- 수평적 확장 horizontal scaling (=scaling out)이 가능하다: 서버의 하드웨어(RAM, CPU 등)를 업그레이드하는 수직적 확장과 다르게, 존재하는 stack에 machine을 추가하는 방식으로 능력을 향상시킬 수 있다.
- 쿼리 반응 속도를 빠르게 한다: 스캔 범위를 줄이기 때문!
- application을 신뢰할 수 있게 만든다: outage가 생겼을 때, un-sharded 데이터베이스와 다르게 단일 shard에만 영향을 줄 확률이 높다. application이 일부라도 작동할 수 있도록 위험을 완화시켜준다.
단점
- 잘못 사용했을 때 risk(데이터 손상, 유실 등)가 큼.
- 데이터가 한 쪽 shards에 쏠려 sharding이 무의미 해질 수 있음.
- 한 번 쪼개게 되면, 다시 un-sharded 구조로 돌리기 어려움.
- 모든 데이터베이스 엔진에서 natively support 되지 않음.
(PosgreSQL은 support)
종류
Key Based Sharding, Range Based Sharding, Directory Based Sharding
Replication
두 개의 이상의 DBMS 시스템을 Master / Slave로 나눠서 동일한 데이터를 저장하는 방식

- Master DBMS에는 데이터의 수정사항을 반영만 하고
- Replication을 하여 Slave DBMS에 실제 데이터를 복사함.
- Query의 대부분은
Select(read) 가 차지.
- 이 부분의 부하를 낮추기 위해 많은
Slave Database를 생성하게 된다면Read(Select)성능 향상 효과를 얻을 수 있음.
Master Database영향없이 로그를 분석할 수 있음
Foreign Data Wrapper
다른 데이터베이스 서버(Oracale 또는 다른 PostgreSQL 서버)의 데이터를 원격으로 조회할 수 있는 Postgresql 확장 기능
“postgres_fdw” is an extension present in the standard distribution, that can be installed with the regular CREATE EXTENSION command:
CREATE EXTENSION postgres_fdw;
CREATE EXTENSION postgres_fdw; GRANT USAGE ON FOREIGN DATA WRAPPER postgres_fdw to app_user; CREATE SERVER shard02 FOREIGN DATA WRAPPER postgres_fdw OPTIONS (dbname 'postgres', host 'shard02', port '5432'); CREATE USER MAPPING for app_user SERVER shard02 OPTIONS (user 'fdw_user', password 'secret');PostgreSQL 9.6 Parallel Query & FDW | Popit
최근에 PostgreSQL 9.6 가 2016 년 9월 29일 Release 되었습니다. ( 최신버전 PostgreSQL 9.6.1 2016-10-27 ) PostgerSQL 9.6 new features 중에서 Parallel Query 와 FDW ( Foreign Data Wrappers ) 이 가장 주목할 만합니다. FDW는 다른 데이터베이스 서버(Orcale 또는 다른 PostgreSQL 서버)의 데이터를 조회할 수 있는 기능입니다.
 https://www.popit.kr/postgresql-9-6-parallel-query-fdw/
https://www.popit.kr/postgresql-9-6-parallel-query-fdw/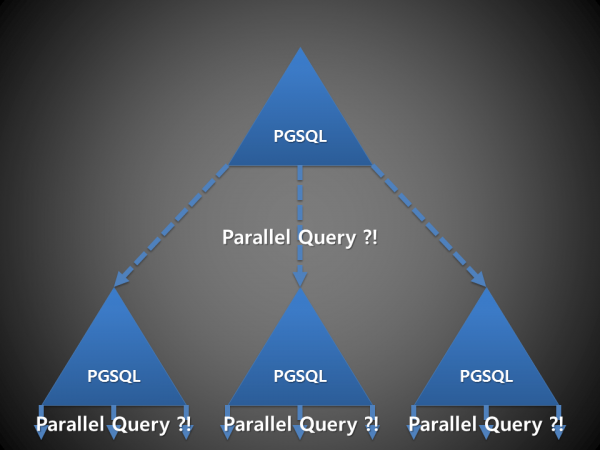
Citus
쿼리와 데이터를 분산하여 관리할 수 있도록 하는 PostgreSQL의 extension. sharding과 replication을 사용해서 수평확장함.
Scaling your Postgres database
Cost-effectively scale out your PostgreSQL database If you are currently using PostgreSQL on a single server and running into CPU, memory or storage bottlenecks, CitusDB can enable you to cost-effectively scale out your database horizontally on commodity servers. Because CitusDB extends the current version of PostgreSQL, there will be little or no impact on your application layer.
 https://www.citusdata.com/solutions/infrastructure/clustered-postgresql
https://www.citusdata.com/solutions/infrastructure/clustered-postgresql
- Auto-sharding of your data
- Dynamic scalability with ability to add or remove nodes without taking the database offline
- Automated reconfiguration of shards after scaling up or down
- Built-in location aware replication
- Automatic failure handling
- 모든 tenant에 빠른 쿼리가능
- database에 sharding logic이 있음
- 단일 노드 PostgreSQL보다 더 많은 데이터 소유가능
- SQL을 포기하는것 없이 Scale out
- high concurrency를 보장하고 동시에 퍼포먼스도 유지
- 빠른 metric 분석가능
- 신규 사용자를 다루기위해 쉽게 scale out 가능
728x90
'Web > Backend' 카테고리의 다른 글
| Linux(Ubuntu)에서 Python 버전 변경하기 (1) | 2021.06.20 |
|---|---|
| Tools for load test (0) | 2021.06.10 |
| [백엔드 기초] 6. Web server(Nginx, Gunicorn, Dramatiq) (0) | 2021.06.01 |
| [백엔드 기초] 5. Docker (0) | 2021.06.01 |
| [백엔드 기초] 4. Database, PostgreSQL (0) | 2021.06.01 |