

Pandas : 수식으로 계산할 수 있고 시각화도 할 수 있는 데이터 분석도구입니다.
엑셀로도 데이터를 분석할 수 있는데 왜 판다스를 사용하는 것일까요?
엑셀로는 힘든 대용량의 데이터를 판다스는 분석할 수 있기 때문입니다.
아래에 첨부된 10 minutes to pandas를 한 번씩 실행해보시면 판다스의 전반적인 것을 익힐 수 있습니다.
(다만, 10 minutes는 문서를 스크롤 하는데 걸리는 시간입니다ㅎㅎ 실제로는 더 오래 걸립니다.)
추가로 같이 첨부된 Pandas Cheat Sheet도 추천드립니다.
우선 판다스를 불러보겠습니다.
import pandas as pd일반적으로 as pd라고 정해줍니다. 이는 쉽게 별칭을 지어준다고 보시면 됩니다.
별칭을 지어주시면 나중에 불러올 때 굳이 다 적지 않으셔도 됩니다.
예를들어, pandas.DataFrame이 아닌 pd.DataFrame로 좀 더 간결하게 사용하실 수 있습니다.
일반적으로 파이썬 라이브러리들은 각각의 통용되는 별칭이 있습니다.
앞으로 나오는 것들은 일반적으로 사용되는 별칭이라고 보시면 됩니다.
DataFrame
Cheet Sheet에 있는 DataFrame을 가져와서 따라해 보도록 하겠습니다.
df = pd.DataFrame(
{"a" : [4, 5, 6],
"b" : [7, 8, 9],
"c" : [10, 11, 12]},
index = [1, 2, 3])
df결과 :
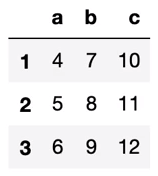
결과를 보시면 a, b, c 컬럼을 가진 DataFrame이 생성된 것을 보실 수 있습니다.
Series
df["a"]라고 컬럼을 출력하게 되면 a 컬럼에 있는 4,5,6의 값이 출력이 되는데 이것을 Series 데이터라고 부릅니다.
df["a"]결과 :

하지만 대괄호를 하나 더 쓰게 된다면 DataFrame 형태로 출력되는 것을 볼 수 있습니다.
df[["a"]]결과 :

결과를 보시면 이렇듯 DataFrame은 2차원의 구조를 가지고 있고,
Series는 1차원의 구조를 가지고 있는 것을 알 수 있습니다.
Subset (일부 값만 불러오기)
# Rows 기준 예시
df[df.Length > 7]
# Columns 기준 예시
df[['width', 'length', 'species']]* 주의 : 두 개 이상의 값을 불러 올때는 DataFrame 형태로 불러와야 합니다.
df["a", "b"]
# 두 개 이상의 값을 불러올 때 Series형태로 불러올 경우 키값 오류가 발생합니다.
df[["a", "b"]]
# DataFrame 형태로 불러와야 합니다.
Summarize Data
Categorical한 값의 빈도수를 구하는 방법입니다.
df["a"].value_counts()결과 :

Reshaping
sort_values, drop
1) "a"컬럼을 기준으로 정렬하기
df["a"].sort_values()결과 :

2) DataFrame 전체에서 "a"값을 기준으로 정렬하기
df.sort_values("a")결과 :

3) 역순으로 정렬하기
df.sort_values("a", ascending=False)결과 :

4) "c"컬럼 drop 하기
df = df.drop(["c"], axis=1)
df
결과 :

Group Data
Groupby, pivot_table
1) "a" 컬럼값을 Groupby하여 "b"의 컬럼값 평균값 구하기
df.groupby(["a"])["b"].mean()결과 :

2) pivot_table로 평균값 구하기
pd.pivot_table(df, index="a")결과 :

--> "a" 컬럼에 있는 값이 4가 두 개가 있기 때문에 그 값의 평균값이 적용이 됩니다.
Plotting
데이터를 가지고 다양한 시각화를 해보실 수 있습니다.
1) 꺾은선 그래프 그리기
df.plot()결과 :

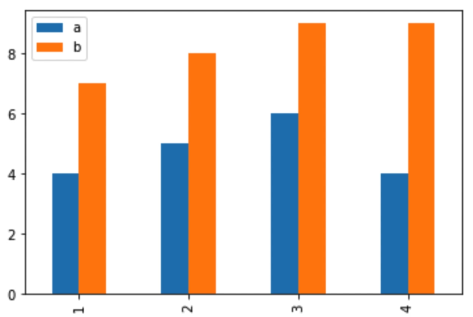
2) 막대그래프 그리기
df.plot.bar()결과 :
3) 밀도함수 그리기
df.plot.density()결과 :

판다스 라이브러리 공식 사이트
pandas - Python Data Analysis Library
pandas pandas is a fast, powerful, flexible and easy to use open source data analysis and manipulation tool, built on top of the Python programming language. Install pandas now!
pandas.pydata.org
10 minutes to pandas
10 minutes to pandas — pandas 1.0.0 documentation
This is a short introduction to pandas, geared mainly for new users. You can see more complex recipes in the Cookbook. Time series pandas has simple, powerful, and efficient functionality for performing resampling operations during frequency conversion (e.
pandas.pydata.org
http://pandas.pydata.org/Pandas_Cheat_Sheet.pdf
'Data Science, ML > Data Science With Python' 카테고리의 다른 글
| 파이썬으로 시작하는 데이터 사이언스 2 - 데이터 분석을 위한 파이썬 속성 기초 (0) | 2021.05.24 |
|---|---|
| 파이썬으로 시작하는 데이터 사이언스 1 - 데이터 분석 환경 구성 (0) | 2021.05.24 |