
바이오마커
- 표현형(phenotype)의 표지가 되는 생물학적 요인(사람들이 암, 당뇨 혹은 면역질환에 걸렸을 때 찾고자 하는 원인)
- -> 치료에 이용할 수 있음
- 돌연변이 유전자, 항원/항체 등
- 질병의 진단, 치료 등에 활용
예전에는 가설 기반 실험 위주였는데, 요즘은 Data-driven 생물학.
경험이나 직관이 아닌 데이터 모으고 분석함. (바이오마커 Candidate로 삼고 실험 후 바이오마커를 찾아냄)
생체 시스템의 계층적 구조와 데이터
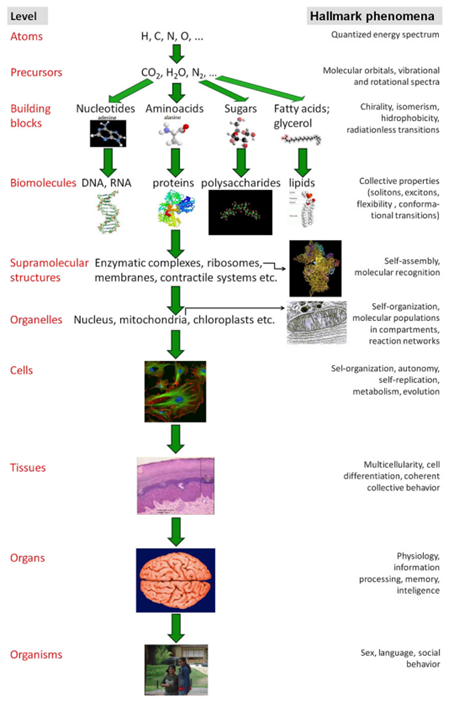
유전자 데이터 -> 세포 내 분자 단위의 가장 정밀한 바이오마커 정보를 포함
고배열 현미경 데이터
X-ray, CT 데이터
혈당, 간수치 데이터
신체 데이터: 안색, 외관, 맥박, 혈압 등
Central Dogma
세포 분자 데이터의 핵심 원리
세포라는 시스템이 어떻게 동작하는가?
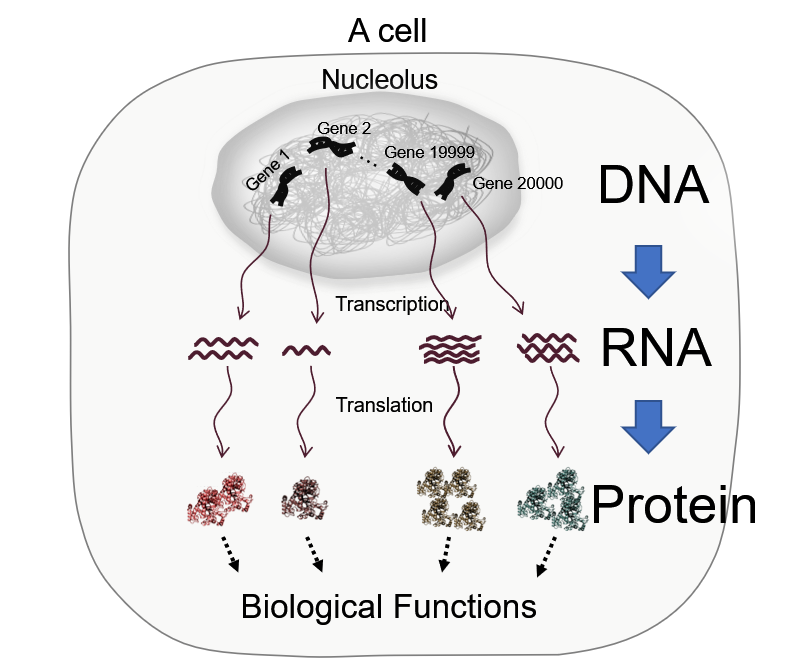
유전자(gene): 단백질 하나를 만들어 낼 수 있는 설계 단위
DNA: 단백질을 만드는 설계 정보, 핵(nucleous)안에서 보호됨, 원본이라고 할 수 있으며 변경이 되면 안됨
RNA: DNA의 정보를 Protein 합성을 위해 전달함(정보 전달 매개체, mRNA)
Protein: RNA의 정보에 따라 합성됨, 생물학적 기능을 수행하는 주체, 20 종류의 아미노산으로 이루어져 있음, 3D 구조

DNA: Genome(A long Sequence), ATGC가 길게 이어진 실타래
Transcriptome(Total cell of RNA): 유의미한 정보를 담고 있는 DNA의 특정 조각들의 모음
Sequencing Technologies
염기서열 정보를 읽어내는 기술
- Sanger sequencing
- Microarray
- NGS (Next Generation Sequencing)

염기 서열 정보를 분석하기 위해 Bio informatics 라는 학문 분야가 생겨났다고 볼 수 있음.
Sanger Sequencing

- 염기 서열의 일부를 떼어낸 뒤 프라이머를 붙임
- 합성되는 위치(길이)가 각각 다름
- 질량 순으로 분석
- 특정 위치에 대한 ATCG 정보를 알아낼 수 있음
Reference Genome
인류 표준 지놈

2000년도 쯤 지놈프로젝트로 인류의 sequencing 정보를 알아낼 수 있게 됨
사람마다 염기 서열의 정보는 99.9%가 동일하고 극히 일부가 다름
사람마다 다른 부분을 비교하기 위해 참고하려고 만든 것이 Reference Genome (평균 지놈)
FASTA file
염기서열 시퀀스를 저장하는 파일 형식 (e.g. human_reference_genome.fasta)

첫줄 > 시퀀스에 대한 정보
차세대 시퀀싱(Next Genearation Sequencing, NGS)
긴 DNA(or RNA)를 짧은 조각(short read)로 자르고, 병렬적으로 시퀀싱하여 빠르고 대량으로 시퀀싱하는 기술
기존의 방식은 손이 많이 가서(노가다) 지나치게 느리다고 비용도 많이 든다는 단점이 있었음 -> 이를 비약적으로 향상

* Illumina: 차세대 시퀀싱 원 탑 회사
Single cell sequencing
(vs Bulk sequencing)
하나의 세포만 선택하여 시퀀싱 하는 기술
Bulk sequencing은 예전엔 어쩔 수 없었다 (Sequencing을 돌리려면 어느 정도 충분한 양이 필요했음)
기술이 발전함에 따라 세포 하나만 가지고도 complete한 정보를 얻을 수 있게 되었음
시퀀싱 기술을 이용한 바이오마커 유전자 분석
(바이오 마커 유전자: 표현형을 유발하는 문제적 유전자)
DNA -> 돌연변이(Mutation) 서열이 있는 유전자 검출
- Somatic mutation : 후천적 변이 (e.g. 암)
- Germline mutation : 선천적 변이 (e.g. 유전병)
RNA -> 과발현/저발현 유전자 검출
- 과발현 : 실험군(e.g. 폐암환자군)에서 이상적으로 양이 많이 발현 되어 있는 유전자
- 저발현 : 실험군(e.g. 폐암환자군)에서 이상적으로 양이 적게 발현 되어 있는 유전자
DNA 분석 - Variant Calling
개인의 변이 서열(바이오마커)을 찾아냄

Mapping(Alignment): Short read 정보를 가지고 원래 어느 위치에 있었는지 알아내는 과정(1/4^200)
RNA 분석 - Gene Expression
개인의 유전자 활성화를 조사함
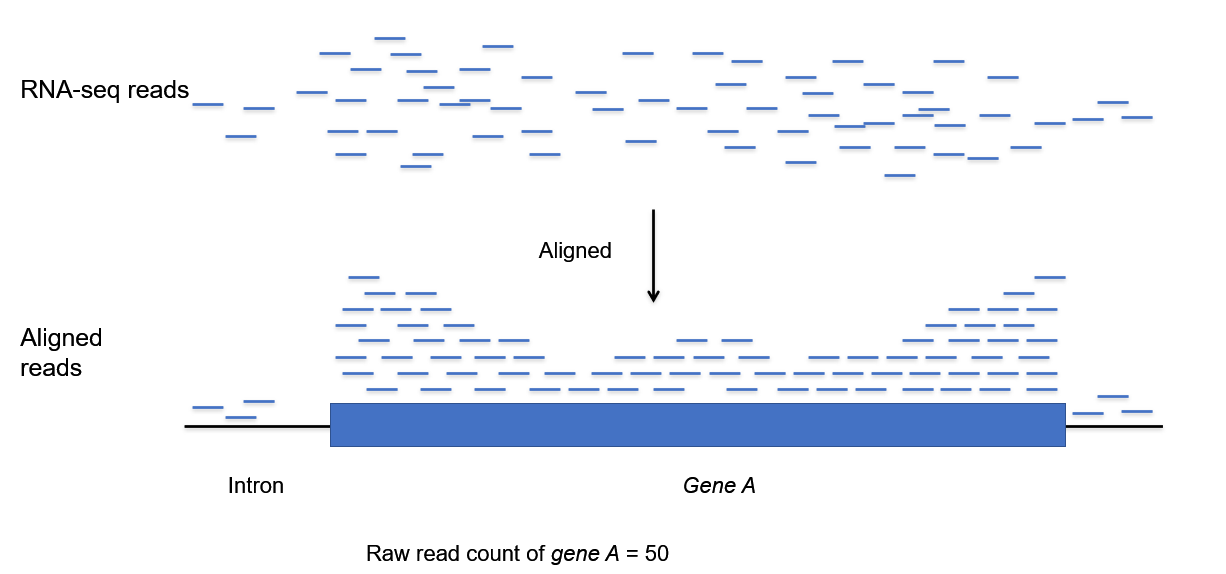
Intron(Intergenic) 쪽에는 mapping을 해봐도 거의 안붙음
몇 개가 붙어있느냐가 중요함. 얼마나 많이 copy가 되어있는가(=얼마나 활성화되어있는가)를 알 수 있기 때문
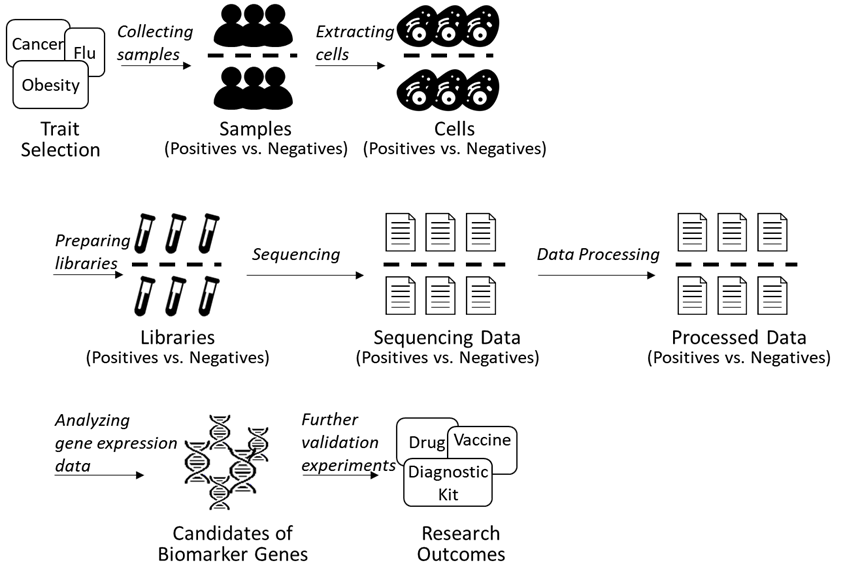
실험/대조군 기반의 유전체 바이오 마커 검출 분석 과정
'Bioinformatics' 카테고리의 다른 글
| Fold change에 따른 DEG 분석(Python) (0) | 2021.08.25 |
|---|---|
| 바이오마커 유전자 분석 (0) | 2021.08.24 |
| TCGA 데이터 (0) | 2021.08.24 |
| 정보의학개론 - 의료정보학 개요 (0) | 2021.08.23 |
| Biopython 설치 (1) | 2021.02.16 |